

The shape of things to come (1): vers le péta-octet et au delà...
Pour appréhender le monde d'après, un premier pas consiste peut être à essayer de voir quelles sont les ruptures déjà présentes dans notre monde... Evidemment, il y a la rupture imposée par les limites physiques, en particulier énergétiques, auxquelles nous sommes en train de nous heurter. Mais il y a aussi les ruptures issues de notre développement technologique... et certaines sont déjà en train de changer notre monde.
J'en ai déjà parlé dans un post précédent mais en fait, sans vraiment expliquer en quoi nous sommes en train de vivre une rupture historique et sans développer quels en sont les enjeux. En fait, ma réflexion là dessus a progressé à l'occasion du mémoire de M2 d'un étudiant d'un master "Systèmes et objets interactifs" de l'école Strate College que je connais via des amis parisiens et avec qui j'ai largement discuté de ces questions.
Le point de départ de son travail est la rupture historique que constitue l'émergence de la datasphère globale, à savoir un ensemble de données partagé à l'échelle planétaire et adossé à des moyens de traitement sans commune mesure avec ceux dont nous disposions auparavant.
Dans le monde d'avant Internet, l'humanité était constituée d'individus ayant chacun accès à un ensemble de données limitées. Pour en donner une image, il suffit de survoler la région des Dombes près de Lyon: on y voit une multitudes de mares, étangs, petits lacs. C'est l'image d'un monde où les diverses collectivités humaines avaient chacune accès à leur petit monde de données.
Par exemple, une famile avait accès à sa propre histoire familiale ou bien avait quelques dizaines (plus rarement quelques centaines) de livres dans la bibliothèque familiale. Typiquement un roman c'est environ un mégaoctet de données brutes. Une datasphère familiale du 20ème siècle, c'est moins d'une centaine de megaoctets de données, quelques giga-octets si on inclus les photos. Autant dire une petite mare de données pour reprendre l'image des dombes.
Passons à l'échelle supérieure qui est celle d'une petite ville ou encore d'un établissement universitaire de petite taille ou encore une bibliothèque privée d'un riche érudit ou d'un collectionnaire. Typiquement, on parlera de quelques milliers de volumes, peut être quelques dizaines de milliers (les sections sciences de la Nature de l'ENS de Lyon contiennent 38000 bouquins). Une datasphère d'une petite ville du 20ème siècle, c'est à dire une bibliothèque de 10000 livres, représente environ 10 puissance 10 octets soit 10 gigaoctets, 100 en incluant des images. Aujourd'hui on stocke cela facilement sur une clé USB qui tient dans la poche... C'est 1% de la capacité d'un disque dur de 1 teraoctets donc autant dire qu'aujourd'hui n'importe quel ordinateur peut stocker l'équivalent d'une telle bibliothèque même si en incluant un fond de quelques milliers d'images. Dans la métaphore des dombes, on est à l'échelle de l'étang...
L'échelle supérieure, c'est celle des grands pays industrialisés qui se dotèrent chacun d'une grande blibliothèque (la BN en France)... Prenons par exemple la bibliothèque du Congrès américain qui est la plus importante au monde. D'après Wikipédia, sa collection comprend en 2007:
- 32,2 millions de livres et autres imprimés (2 fois les réserves de la Bibliothèque nationale de France)
- 61,4 millions de manuscrits
- 12,5 millions de photographies
- 5,3 millions de plans et de cartes
- 5,5 millions de disques
Toujours en prenant de l'ordre du megacotet par livre et pour chaque autre document (qui sont environ 100 millions), la bibliothèque du Congrès américain représente un volume de données brutes de l'ordre de 10 puissance 14 octets soit 100 teraoctets. C'est trop pour un simple particulier mais cela tiendrait dans un petit centre de données comme celui d'une université ou d'une grosse PME. Telle était donc la taille des plus grands "lacs de données" disponibles dans le monde d'avant l'Internet.
Dans le monde d'avant, il y avait une interconnexion de ces différentes datasphères, mais elle se faisait à vitesse lente via l'édition, la vente et la circulation des livres. La télévision a certes changé la donne mais n'a pas modifié fondamentalement cette image d'un monde de données fragmenté ressemblant plus aux dombes qu'à l'océan Pacifique.
Aujourd'hui, en 2012, nous avons radicalement changé de monde: une partie significative de l'humanité (entre 1/6ème et 1/5ème) a un accès direct à la datasphere globale par l'Internet. Et c'est là que réside la rupture qui s'est produite à la fin du siècle dernier: le paysage des Dombes a été remplacé par un océan de données global.
De plus le développement de la puissance de calcul et des moyens de stockage (merci Mr. Albert Fert) a considérablement démultiplié nos capacités à générer, transformer et traiter ces données. Récemment, Eric Schmidt (PdG de Google) estimait que l'Internet représente de l'ordre de 5 millions de teraoctets de données (10 puissance 18 octets soit 10000 bilbiothèques du congrès), et que Google en avait indexé de l'ordre de 200 téraoctets... On estime qu'environ 75 millions de serveurs tournent sur la planète mais ce chiffre est peut être sous estimé d'un facteur 5.
Pour avoir une vague idée de la puissance de traitement nécessaire, Google disait processer en 2007 de l'ordre de 20 péta-octets (1 po = 10 puissance 15 soit 1000 tera octets) de données par jour ce qui est absolument considérable... Evidemment ce chiffre est un flux qui correspond au traitement effectué pour indixer le contenu d'Internet et pour répondre aux requêtes utilisateurs. Mais en terme de puissance de calcul, c'est considérable. Pour avoir une idée plus précise de ce que représente, la consommation d'énergie totale des datacenter à l'échelle planétaire est de l'ordre de grandeur de celle d'un pays avancé de quelques millions d'habitants comme la Suède.
On voit donc que le nouvel ordre de grandeur ce n'est plus le livre (le méga-octet), ni même la bibliothèque municipale (quelques téra-octets), ni même la bibliothèque du congrès (quelques centaines de tera-octets) mais le péta-octet et au delà. Pour avoir une idée de ce que cela représente, quelques ordres de grandeurs... Un péta-octet c'est:
- un milliard de romans sans fioritures,
- plus d'un million de CD ou quelques dizaines de milliers de bluray,
- 13 ans de TV HD en continu (compressé),
- le code ADN complet non comprimé d'un million de personnes (après compression, d'une centaine de millions de personnes)!
Et pour bien visualiser cette révolution, voici un petit graphique tiré du Washington Post (cliquez dessus pour agrandir) qui montre très clairement que le point de transition est la décennie que nous venons de vivre:
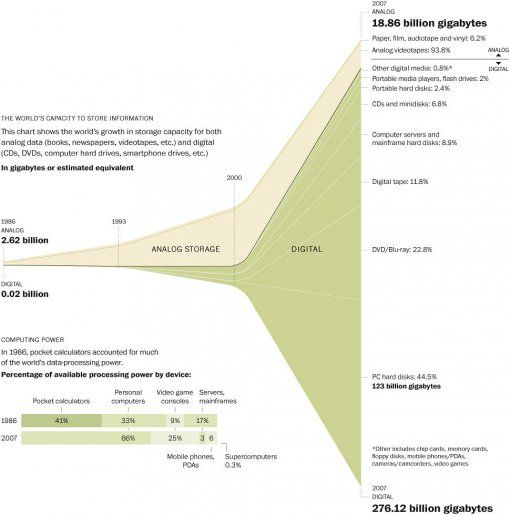
Après la révolution industrielle, nous sommes donc entrés dans un nouvel age et c'est ce que je vais essayer d'explorer dans cette série de posts...
A suivre...



/http%3A%2F%2Fstorage.canalblog.com%2F99%2F47%2F192974%2F131367499_o.png)
/https%3A%2F%2Fassets.over-blog.com%2Ft%2Fcedistic%2Fcamera.png)
/http%3A%2F%2Fstorage.canalblog.com%2F90%2F24%2F192974%2F131357758_o.png)
/https%3A%2F%2Fstorage.canalblog.com%2F09%2F97%2F192974%2F77517457_o.jpg)
/https%3A%2F%2Fstorage.canalblog.com%2F23%2F42%2F192974%2F77100306_o.jpg)
/https%3A%2F%2Fstorage.canalblog.com%2F24%2F78%2F192974%2F76695701_o.jpg)
/https%3A%2F%2Fstorage.canalblog.com%2F42%2F09%2F192974%2F74544475_o.jpg)
/https%3A%2F%2Fstorage.canalblog.com%2F19%2F76%2F192974%2F67945170_o.jpg)